This article describes what data translationCore (tC) uses to display data, and how that data is used.
Data Flow in the translationWords Tool

translationWords (tW) is a tool inside of tC that facilitates checking Key Terms, Other Terms, and names for consistency and accuracy. One of the beauties of tC is that the key terms that are being checked show up highlighted in any aligned translation in the Scripture Pane (the pane across the top labeled “Step 1. Read”).
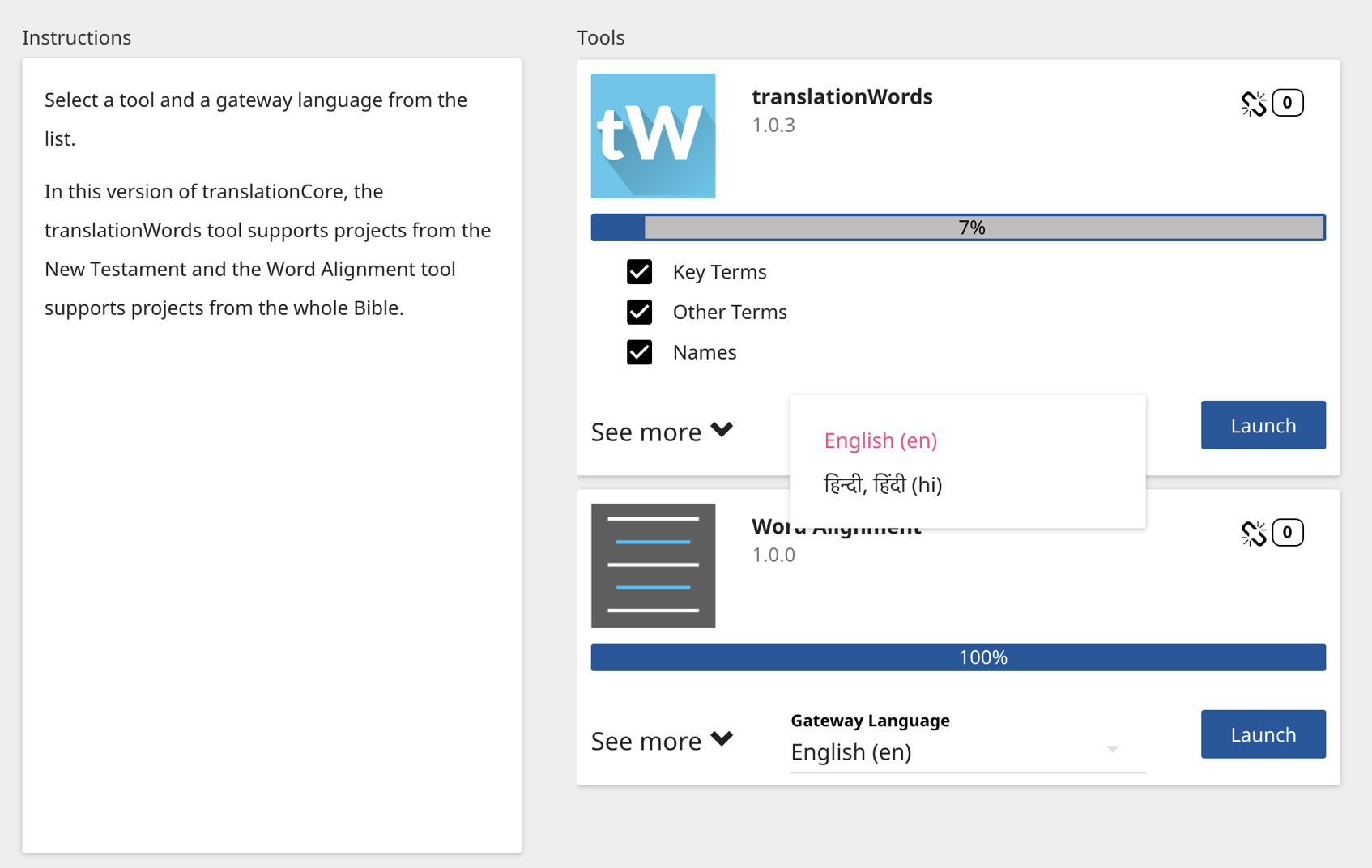
tC also is built so that all of the data can be displayed in any Gateway Language (GL). On the tool card, when all the requisite content is completed and in tC, a new GL will show up in the dropdown list on the tool card on tool selection screen.
A key goal is that all of tC be available in all the GL languages so that anybody in the world will be able to check their translations from a language they know.

To achieve this goal, all data has been based off of the Original Languages (the unfoldingWord Greek New Testament (UGNT) for the New Testament and the unfoldingWord Hebrew Bible (UHB) for the Old Testament).

For as nice as these texts display on a screen or in print, there is a lot of embedded data in the raw files that does not appear nearly so pretty.

All the Original Language words are captured in the raw data (red). Each Original Language word has a lot of metadata attached to it (green). Each word has is has its lemma (dictionary form), its Strong’s Number (a unique number assigned to each Original Language dictionary form), and a morphology code (part of speech). Each word is easily distinguishable with an opening and closing word marker (blue).
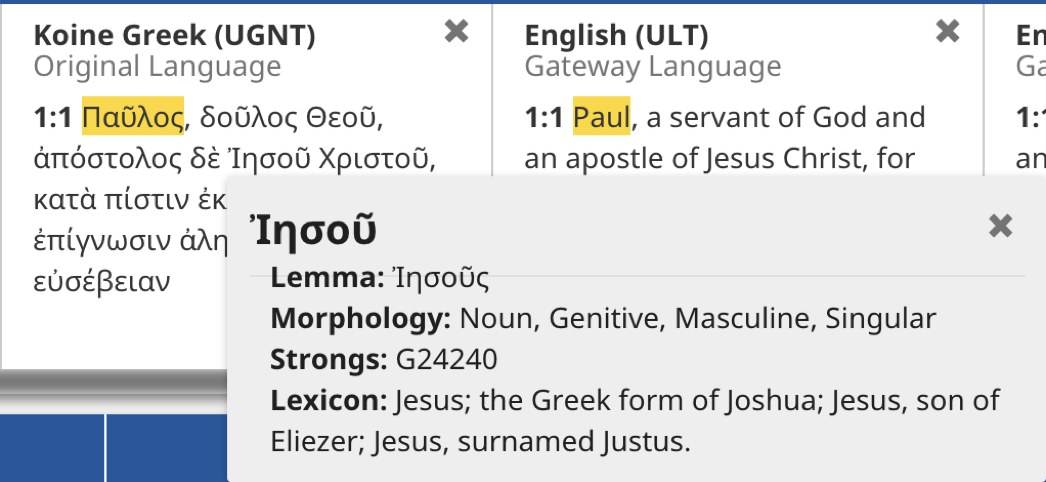
The embedded information in the UGNT/UHB gives tC enough information to show the Lemma, an easily decipherable code to show the Morphology, and the Strong’s Number. With the Strong’s Number, a quick look-up to a simple Lexicon gives a simple definition. This is available by clicking on any Original Language word in the app.

The final piece of information in the raw Original Language files is the tags that delineate which words make up the translationWords. Single translationWords are indicated with a link inside the word makers.

translationWords that span multiple Original Language words are delineated with an opening marker (\k-s ... \*) and a closing marker (\k-e\*).

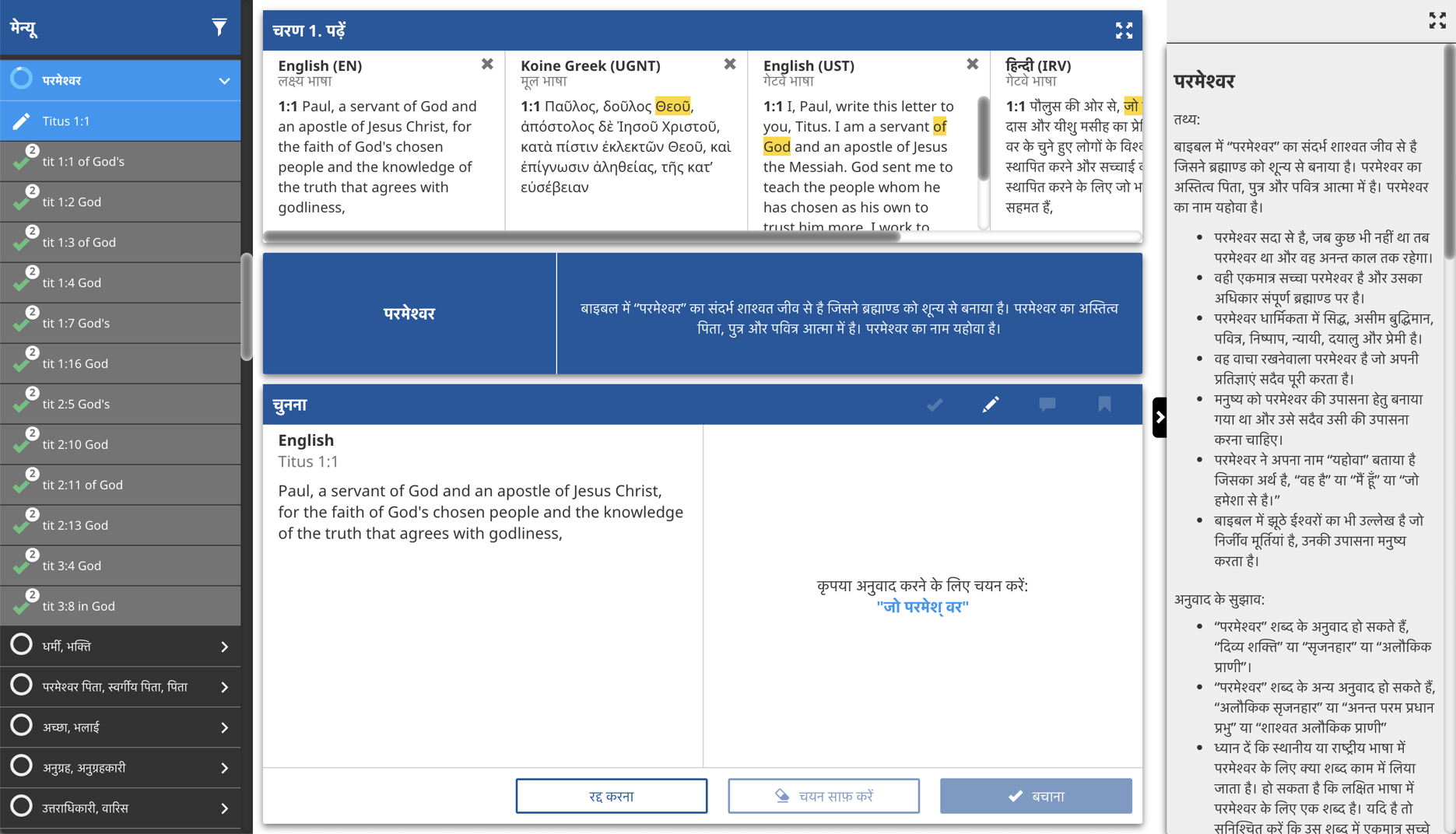
The next piece of content is the actual translationWords articles themselves. They are divided into broad categories (Key Terms, Other Terms, and Names). Each tW has a brief article that defines the term and in some cases gives synonyms or other ways it may be translated.
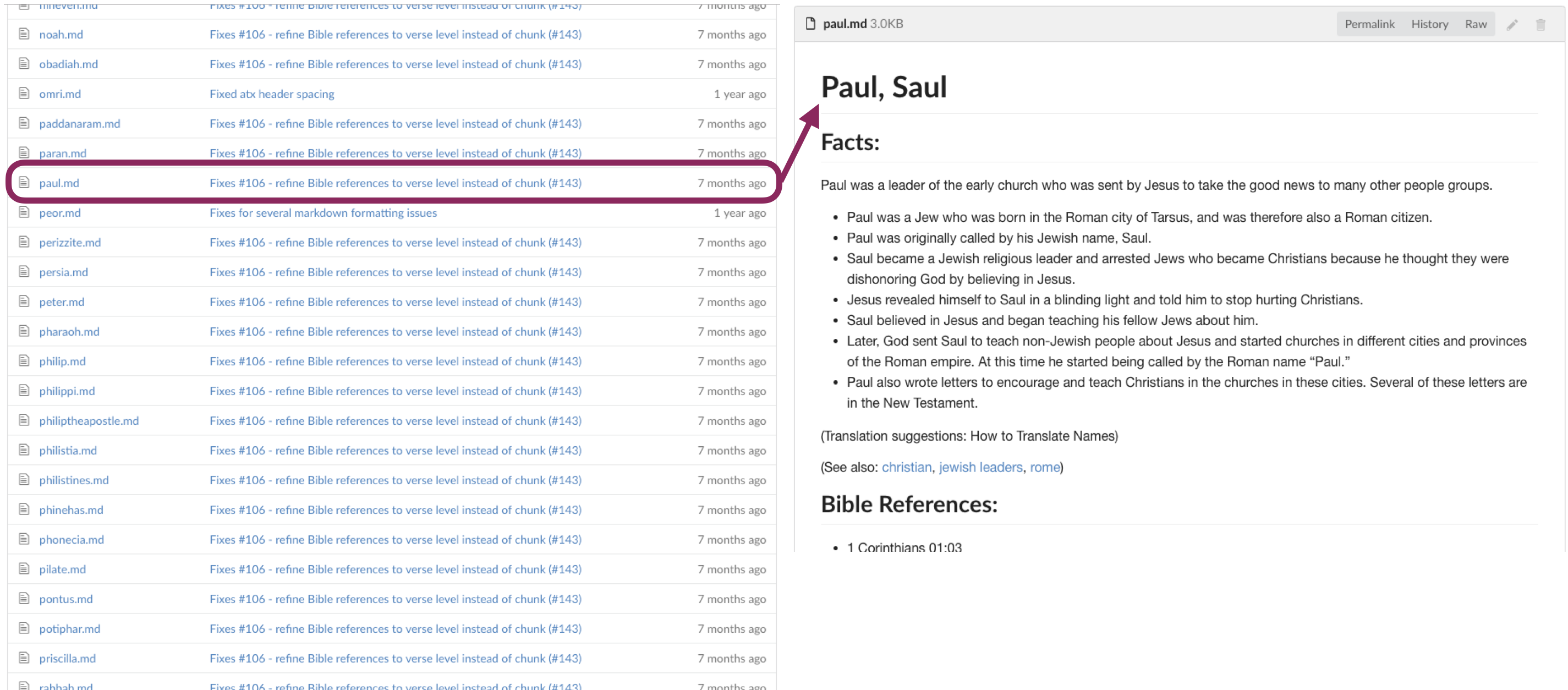
Each tW article has a unique name (which corresponds to the link in the UGNT/UHB) and an article that goes along with it.

When all this content is pulled into tC, it works like this: tC looks in the UGNT/UHB for tW tags (green circle). When a tag is found, the corresponding Original Language words are highlighted in the Scripture Pane (maroon). The tW tag also indicates which tW article should be called up. The first part of the article is displayed in the blue check info pane while the whole article is displayed in the gray tHelps pane (green arrows). But how does tC know which words should be highlighted in the other translations in the Scripture Pane?
The data needed for knowing which words to highlight come from each resource translation.

Bible translations are normally stored in the industry standard format called USFM. This is very human readable with some light markup notation for verses, chapters, footnotes, etc.
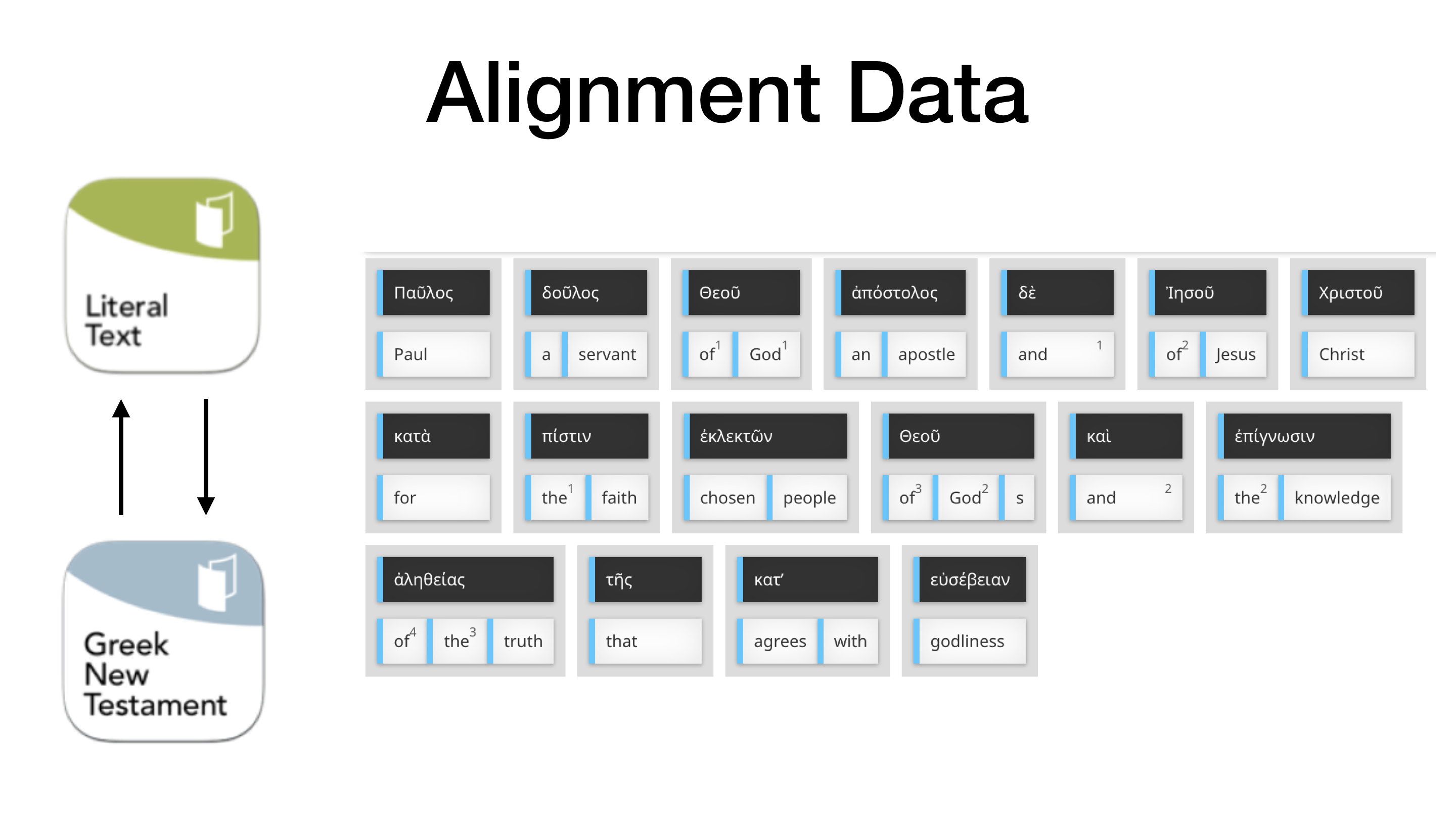
The data that tC needs to be able to accurately display the highlight comes from alignment data, or data that shows the correlation of the translation to the Original Language. To facilitate the creation of this alignment data, the tC team created the Word Alignment Tool.

This alignment data is captured in the latest version of the USFM spec, USFM3. All of the translation is still retained (green) but all of the UGNT/UHB is embedded within the translation (red).

These two texts are arranged in such a way that the alignments between the Original Language words and the words of the translation are maintained.
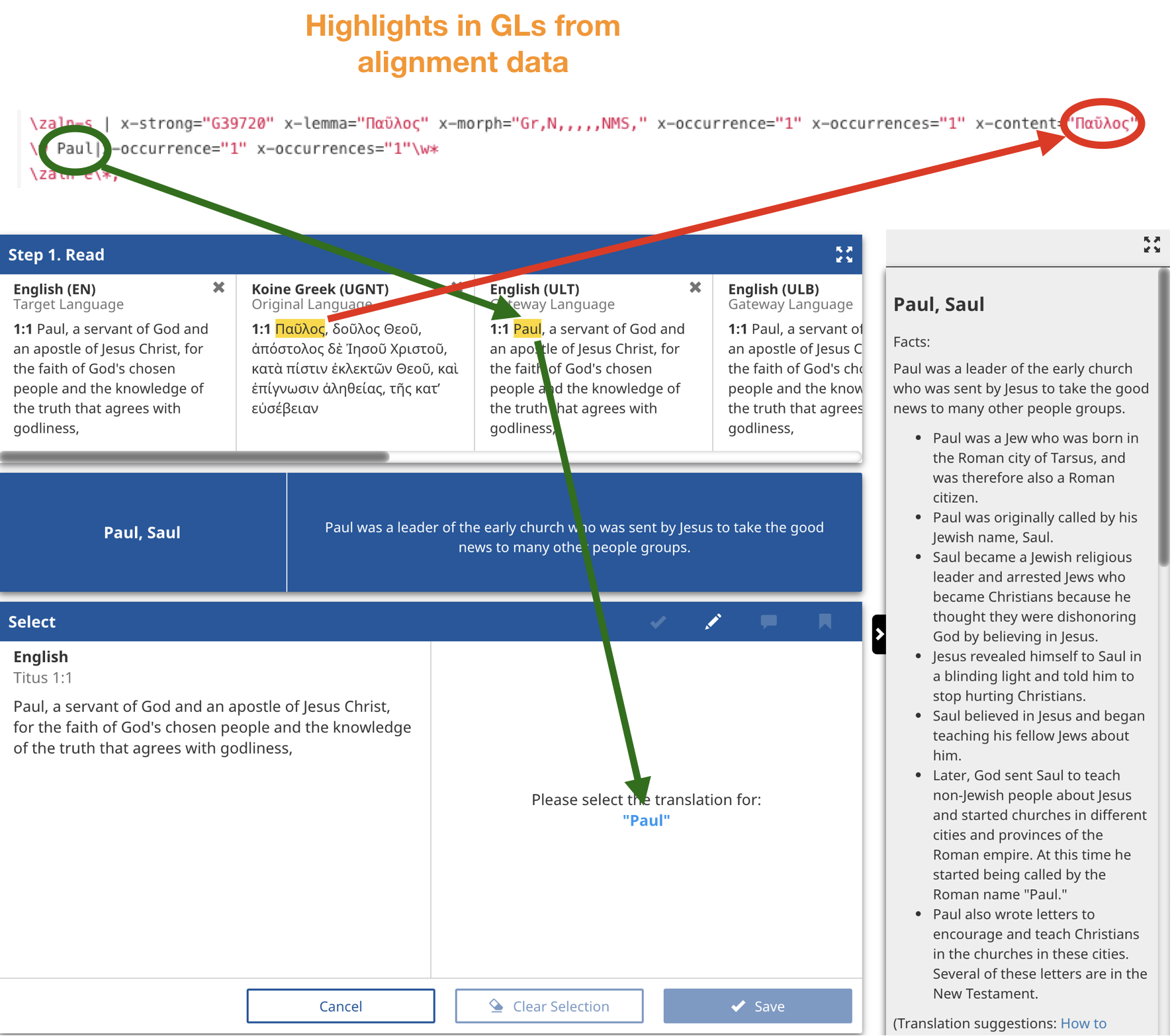
The alignment data between the translation and the Original Language text (UGNT/UHB) is the last piece of data needed to show the highlight in that translation. The Original Language word has already been identified by the tW tag in the UGNT/UHB. Now the Original Language word(s) (red) is looked up in the alignment data and the corresponding word(s) in the translation (green) are highlighted in the Scripture Pane as well as displayed in the check pane below.
Data Flow in the translationNotes Tool

The translationNotes (tN) Tool is a tool inside of tC that looks and functions very similarly to the tW tool. But while the tW tool checks important words, translationNotes checks things like figures of speech, grammatical concepts, cultural issues, and the like.
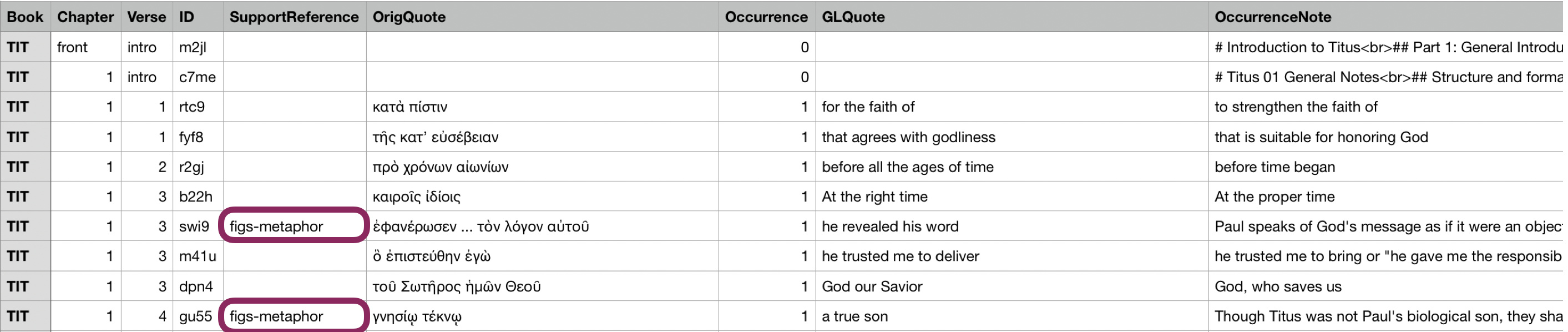
The basic data flow for the tN tool is similar to the tW tool, but a little different. The first difference is that the data for the tN is in a separate tN file in Tab Separated Value (TSV) format. Though there are many tN’s for any given book, the only ones displayed in tC are the ones that have a tag to a translationAcademy (tA) article (maroon).
Each tag in tN has a corresponding tA article by that same name. For all of these cases, the tA article describes a general topic, like Metaphor, Hypothetical Situations, Abstract Nouns, etc.
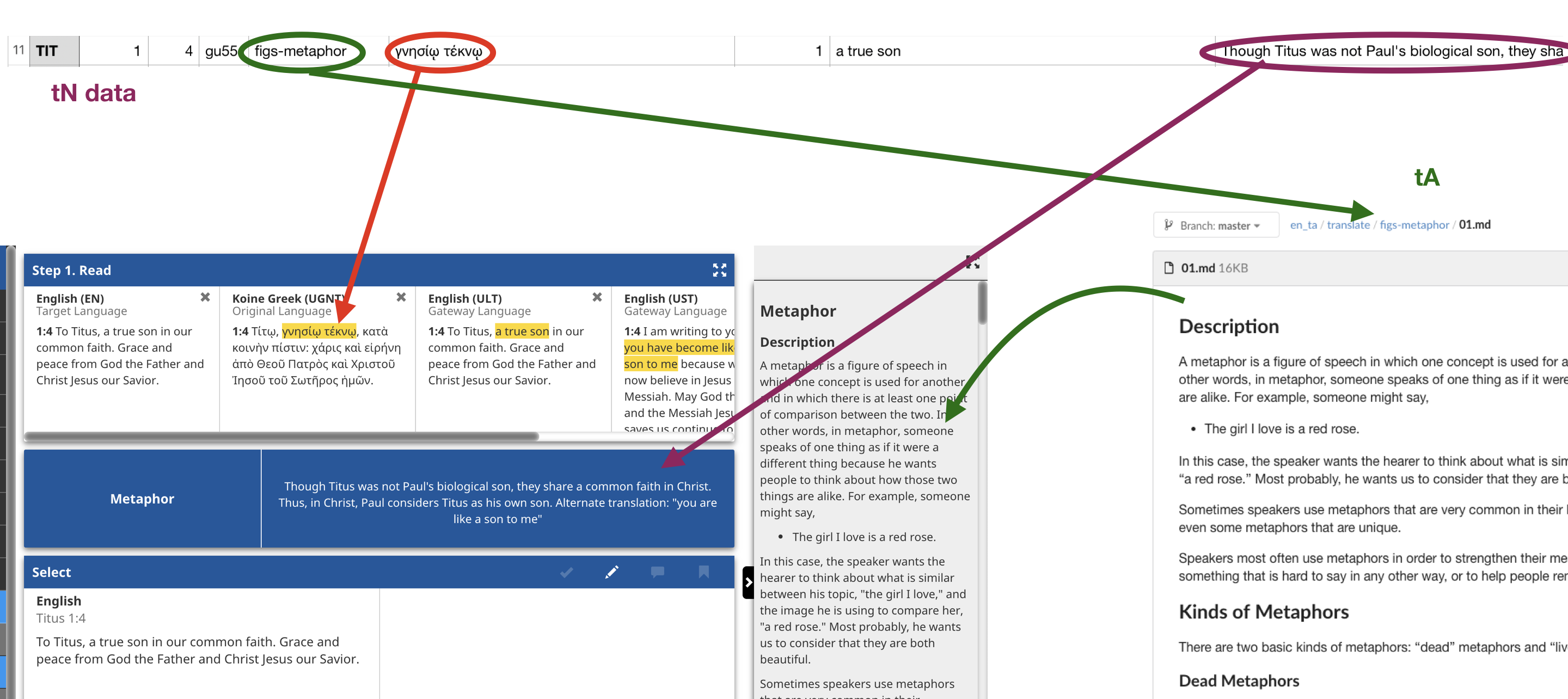
The tN file shows which words need to be highlighted in the Original Language (red). The tag in the tN links to a tA article which is displayed in the gray tHelps Pane on the right-hand side (green). The text for the blue Check Info Pane is also populated by the data in the tN (maroon).

To display the highlights in other translations, again alignment data is needed. In this particular example, the first Greek word (γνησίῳ) is aligned to only one English word (true) while the second Greek word (τέκνῳ ) is aligned to two English words (a and son).

With the alignment data, all the data is now present for the tN tool to show the highlight in the aligned translation and show what needs to be selected in the Check Info card (orange).
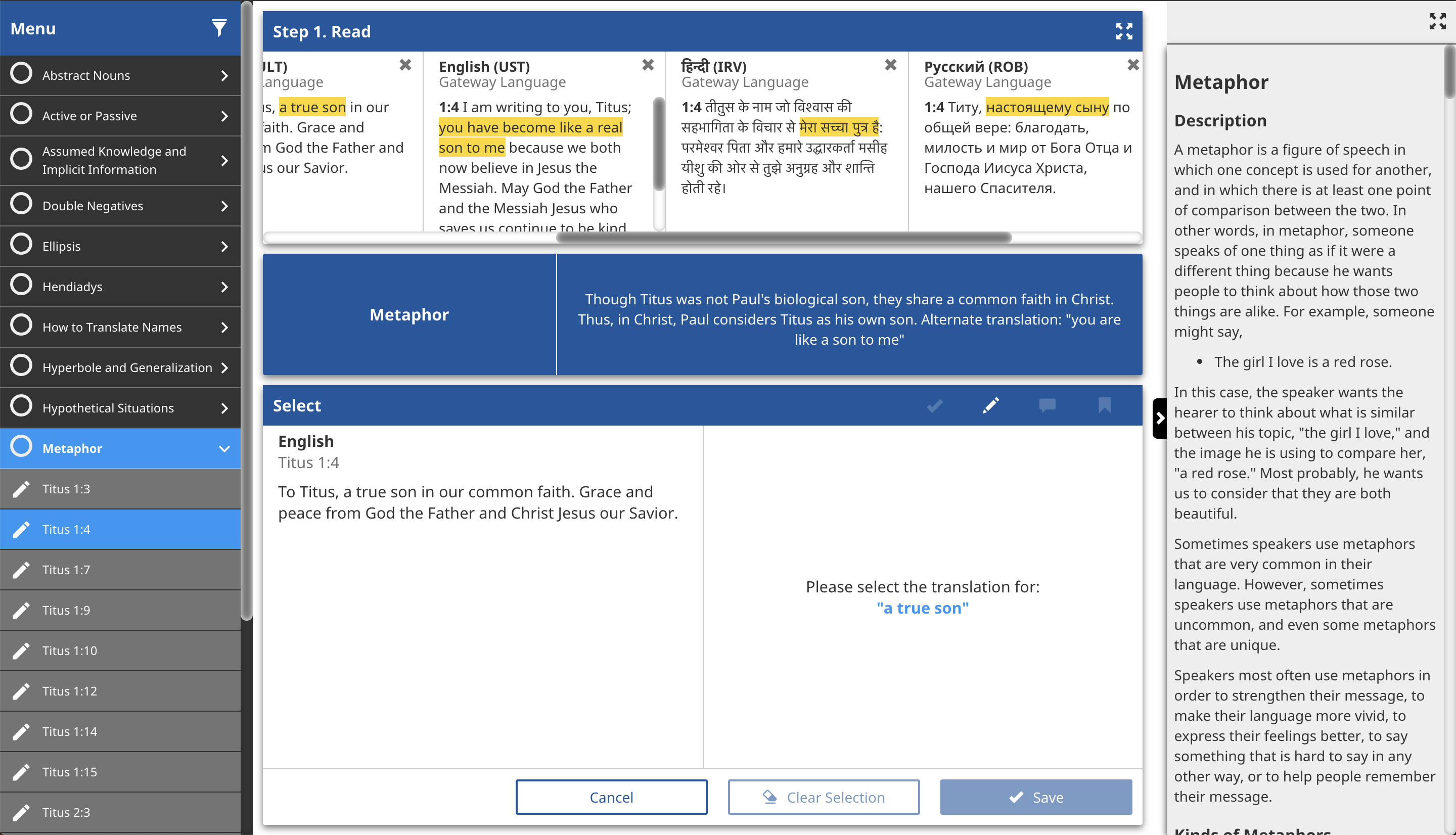
This data flow allows any aligned translation in any language to show the corresponding highlight. (In this example, a literal text, a very dynamic text, Hindi, and Russian!)
This is an overview of how the data in tC flows. I hope you found it helpful. Happy checking!